
David Kirk, Nvidia's Chief Scientist, is an incredibly busy man with an even busier schedule. In the last four weeks, he's been touring some of the top universities in China, Japan and Europe to give guest lectures on how Nvidia's technologies will impact the future of computing—and not just graphics.
We managed to catch up with him in London on the final leg of his European tour at the Department of Computing at Imperial College for an exclusive chat about where Nvidia (and the industry) is moving in the future.
Kirk's role within Nvidia sounds many times simpler than it actually is: he oversees technology progression and he is responsible for creating the next generation of graphics. He's not just working on tomorrow's technology, but he's also working on what's coming out the day after that, too.
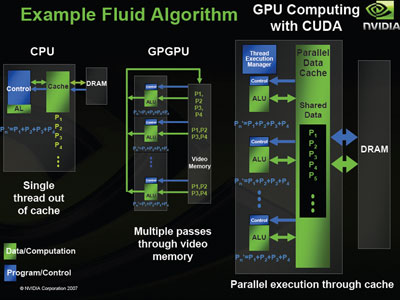
Even though David had probably finished with G80 long before we spoke to him in July 2005, he couldn't talk about that for obvious reasons. His role has changed a little since G80's launch because of the introduction of a technology called CUDA, which stands for Compute Unified Device Architecture. For those that aren't familiar with this technology, it basically means that the CUDA-enabled GPUs (i.e. members of the GeForce 8- and 9-series) can also be used as massively parallel computing devices, running programs written in C.

"Sure," acknowledged David. "I think that if you look at any kind of computational problem that has a lot of parallelism and a lot of data, the GPU is an architecture that is better suited than that. It's possible that you could make the CPUs more GPU-like, but then you run the risk of them being less good at what they're good at now – that's one of the challenges ahead [for the CPU guys].
"The biggest problem ahead for GPUs is that they are designed to be multi-core and we've made all of the mistakes before," David explained, while laughing. "OK, maybe not all of them – but we've learned a bunch of things over the years through the course of building massively parallel GPUs.
"GPUs are able to very efficiently run a large number of threads, but there is still a problem with multi-core CPUs – if the average user downloads one of those CPU utilisation meters that shows the multiple cores, they'll see that they're not using those cores most of the time so it's really a waste of money. For most people, if they buy a dual-core CPU or a low speed grade quad-core, that would be great. It's probably a good place to be, as we don't think you need much more than that."
Just about every major chip maker in the industry believes that parallel processing is the future – multi-core CPUs have been around for a few years now and at the same time GPUs have become more flexible and more CPU-like. This seemed like a great place to further our discussions on the role of the CPU in the future – will the CPU ever replace the GPU, or vice versa? David was very short in his answer – offering a simple "No."
He smiled in a rather convincing manner, while I laughed because I wasn't expecting an answer as short as that. "The reason for that is because GPUs and CPUs are very different. If you built a hybrid of the two, it would do both kinds of tasks poorly instead of doing both well," he said.
 "A chip with some CPU cores and some GPU cores on it would be a great product for the low end for people that don't care that much about performance. However, most of our customers ask us for more computing power—not for less—so I wouldn't want to take some of my silicon area and devote it to a CPU.
"A chip with some CPU cores and some GPU cores on it would be a great product for the low end for people that don't care that much about performance. However, most of our customers ask us for more computing power—not for less—so I wouldn't want to take some of my silicon area and devote it to a CPU.
"On the CPU, you can rip through tasks sequentially and the cache helps with that. It's a good architecture—I want to make that clear before I go any further, as it always seems like I'm picking on the CPU—because for what it does, it does it very well. If you took the same task and ran it on a GPU, it would take forever.
"However if you have a lot of things to do and they're heavily threaded, it's going to take a long time for the CPU to do those tasks. Whereas with a GPU, it will probably take about the same time or maybe a little longer than a CPU to do each individual task, but the fact you can do a lot of them at the same time means you can complete those tasks quicker.
"The ability to do one thing really quickly doesn't help you that much when you have a lot of things, but the ability to do a lot of things doesn't help that much when you have just one thing to do. However, if you modify the CPU so that it's doing multiple things, then when you're only doing one thing it's not going to be any faster.
"It's this paradox where there are two regimes – there's a little and a lot. There isn't really a place for sort-of-a-lot. Important numbers are one and 12,000 – I believe that 16, for example, is not an important number. If you merge the CPU and GPU, you end up in a place I like to call no man's land – that's exactly where the number 16 is on my scale," Kirk explained.
We managed to catch up with him in London on the final leg of his European tour at the Department of Computing at Imperial College for an exclusive chat about where Nvidia (and the industry) is moving in the future.
Kirk's role within Nvidia sounds many times simpler than it actually is: he oversees technology progression and he is responsible for creating the next generation of graphics. He's not just working on tomorrow's technology, but he's also working on what's coming out the day after that, too.
Even though David had probably finished with G80 long before we spoke to him in July 2005, he couldn't talk about that for obvious reasons. His role has changed a little since G80's launch because of the introduction of a technology called CUDA, which stands for Compute Unified Device Architecture. For those that aren't familiar with this technology, it basically means that the CUDA-enabled GPUs (i.e. members of the GeForce 8- and 9-series) can also be used as massively parallel computing devices, running programs written in C.
Dr. David Kirk, Chief Scientist at Nvidia
CPUs and GPUs
It's fair to say that Nvidia has been playing down the need for a fast CPU for some time now, and with the arrival of GPU-accelerated applications like PhysX and RapiHD that have been developed with (or ported to, in the case of PhysX) CUDA, you have to wonder if the paradigm is about to change. I wasn't just interested in the general computing applications here though, I was eager to find out if more general graphics problems could be offloaded from the CPU."Sure," acknowledged David. "I think that if you look at any kind of computational problem that has a lot of parallelism and a lot of data, the GPU is an architecture that is better suited than that. It's possible that you could make the CPUs more GPU-like, but then you run the risk of them being less good at what they're good at now – that's one of the challenges ahead [for the CPU guys].
"The biggest problem ahead for GPUs is that they are designed to be multi-core and we've made all of the mistakes before," David explained, while laughing. "OK, maybe not all of them – but we've learned a bunch of things over the years through the course of building massively parallel GPUs.
"GPUs are able to very efficiently run a large number of threads, but there is still a problem with multi-core CPUs – if the average user downloads one of those CPU utilisation meters that shows the multiple cores, they'll see that they're not using those cores most of the time so it's really a waste of money. For most people, if they buy a dual-core CPU or a low speed grade quad-core, that would be great. It's probably a good place to be, as we don't think you need much more than that."
Just about every major chip maker in the industry believes that parallel processing is the future – multi-core CPUs have been around for a few years now and at the same time GPUs have become more flexible and more CPU-like. This seemed like a great place to further our discussions on the role of the CPU in the future – will the CPU ever replace the GPU, or vice versa? David was very short in his answer – offering a simple "No."
He smiled in a rather convincing manner, while I laughed because I wasn't expecting an answer as short as that. "The reason for that is because GPUs and CPUs are very different. If you built a hybrid of the two, it would do both kinds of tasks poorly instead of doing both well," he said.
"A chip with some CPU cores and some GPU cores on it would be a great product for the low end for people that don't care that much about performance. However, most of our customers ask us for more computing power—not for less—so I wouldn't want to take some of my silicon area and devote it to a CPU."On the CPU, you can rip through tasks sequentially and the cache helps with that. It's a good architecture—I want to make that clear before I go any further, as it always seems like I'm picking on the CPU—because for what it does, it does it very well. If you took the same task and ran it on a GPU, it would take forever.
"However if you have a lot of things to do and they're heavily threaded, it's going to take a long time for the CPU to do those tasks. Whereas with a GPU, it will probably take about the same time or maybe a little longer than a CPU to do each individual task, but the fact you can do a lot of them at the same time means you can complete those tasks quicker.
"The ability to do one thing really quickly doesn't help you that much when you have a lot of things, but the ability to do a lot of things doesn't help that much when you have just one thing to do. However, if you modify the CPU so that it's doing multiple things, then when you're only doing one thing it's not going to be any faster.
"It's this paradox where there are two regimes – there's a little and a lot. There isn't really a place for sort-of-a-lot. Important numbers are one and 12,000 – I believe that 16, for example, is not an important number. If you merge the CPU and GPU, you end up in a place I like to call no man's land – that's exactly where the number 16 is on my scale," Kirk explained.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.