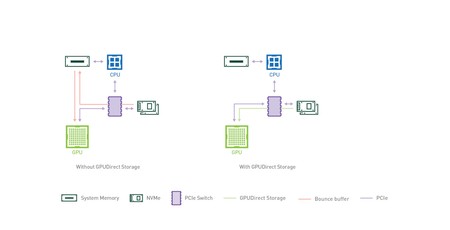
Nvidia has released technical details of GPUDirect Storage, an upcoming technology which will allow GPUs to access data directly from storage devices without going through the CPU - though it has its eye firmly on the data centre, rather than gamers.
The birth of general-purpose graphics processing unit (GPGPU) offload, where highly-parallelisable tasks are shuffled onto a many-core GPU to dramatically accelerate their performance compared to running the same workload on a CPU, brought with it an inherent limitation to how much extra performance you can gain: A bottleneck that sees data needing to be handled by the CPU before it can be passed to the GPU. It's a bottleneck that affects even the highest-end of hardware: Nvidia's own DGX-2 supercomputer-in-a-box product is limited to 50GB/s total bandwidth as everything passes through the CPU on its way to or from the GPU.
GPUDirect Storage builds on Nvidia's earlier GPUDirect RDMA, which concentrated on linking GPUs to network cards, and does exactly what it says on the tin: A GPUDirect Storage-enabled system can pull data from selected storage devices directly into the GPU memory without having to pass through the CPU or system memory first. The result, the company claims: An increase in total achievable bandwidth to and from GPU memory from 50GB/s to almost 200GB/s in a DGX-2 - totalling up what can be transferred from system memory, local drives, and over the network.
This increased bandwidth will, initially at least, be focused on improving performance for data centre workloads, rather than games. 'Data analytics applications operate on large quantities of data that tends to be streamed in from storage. In many cases the ratio of computation to communication, perhaps expressed in flops per byte, is very low, making them IO [input/output] bound,' explain Nvidia's CJ Newburn and Adam Thompson in a deep-dive into the technology. 'In order for deep learning to successfully train a neural network, for example, many sets of files are accessed per day, each on the order of 10MB and read multiple times. Optimization of data transfer to GPU, in this case, could have a significant and beneficial impact on the total time to train an AI model. In addition to data ingest optimizations, deep learning training often involves the process of checkpointing – where trained network weights are saved to disk at various stages of the model training process. By definition, checkpointing is in the critical I/O path and reduction of the associated overhead can yield shorter checkpointing periods and faster model recovery.
'[GPUDirect Storage] provides value in several ways: 2x-8x higher bandwidth with data transfers directly between storage and GPU; Explicit data transfers that don’t fault and don’t go through a bounce buffer are also lower latency; we demonstrated examples with 3.8x lower end-to-end latency; avoiding faulting with explicit and direct transfers enables latency to remain stable and flat as GPU concurrency increases; use of DMA engines near storage is less invasive to CPU load and does not interfere with GPU load; the ratio of bandwidth to fractional CPU utilisation is much higher with GPUDirect Storage at larger sizes.
'We observed that GPU utilisation remains near zero when other DMA engines push or pull data into GPU memory; the GPU becomes not only the highest-bandwidth computing engine but also the computing element with the highest IO bandwidth, e.g. 215GB/s vs. the CPU’s 50GB/s; all of these benefits are achievable regardless of where the data is stored – enabling very fast access to petabytes of remote storage faster than even the page cache in CPU memory; bandwidth into GPU memory from CPU memory, local storage, and remote storage can be additively combined to nearly saturate the bandwidth into and out of the GPUs. This becomes increasingly important and data from large, distributed data sets is cached in local storage, and working tables may be cached in CPU system memory and used in collaboration with the CPU.'
More information on GPUDirect Storage, which is currently running through the process of being readied for commercial release, can be found on the Nvidia blog.







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.