
Show me the cache
The first Core i7 CPUs to launch are native quad cores - there will be no dual cores until the budget Havendale CPUs arrive and eight core variants are currently limited to the multi-socket server level Nehalem-EX, aka Beckton. The Core i7 processor drops the large, shared L2 cache in favour of much smaller (256KB), but 4ns faster, dedicated L2 cache instead that is also buffered by a large 8MB L3 cache.It's important to note that the L3 cache exists in the "Uncore" section, which works at a lower frequency to the cores - this is identical to how AMD handles its L3 cache, including linking the L3 cache to its memory controller frequency, although unlike HyperTransport, the QPI is not frequency linked.
Since all the caches are inclusive, instead of exclusive, it means that 1.26MB of the 8MB is lost to mirroring what is in the other caches, however this also means it acts as a snoop filter. For example, if a core has a local L1 and L2 cache miss, it can check L3 cache without interfering with the other cores, freeing their resources and saving time.
Each level of cache takes considerably longer to access than the last, and while Core i7 now has 35ns 8MB shared across four cores, rather than 15ns 6MB shared across just two, means not only less, but slower on-die cache per core. The offset to this is that the memory access latency is ~40 percent less than of the Core 2's because the L3 cache is closely linked to the memory controller. While this is important, an efficient, low latency link between the memory/L3 cache and the Execution cores is essential for the best performance.
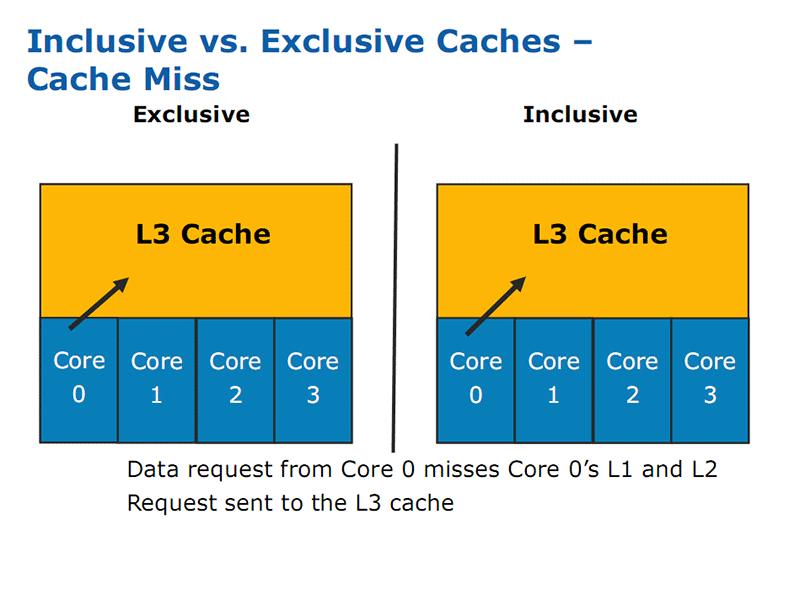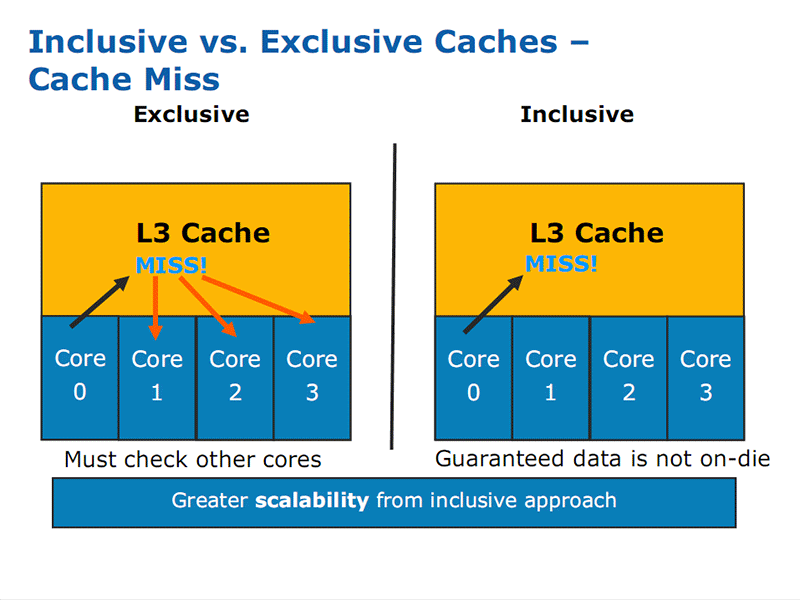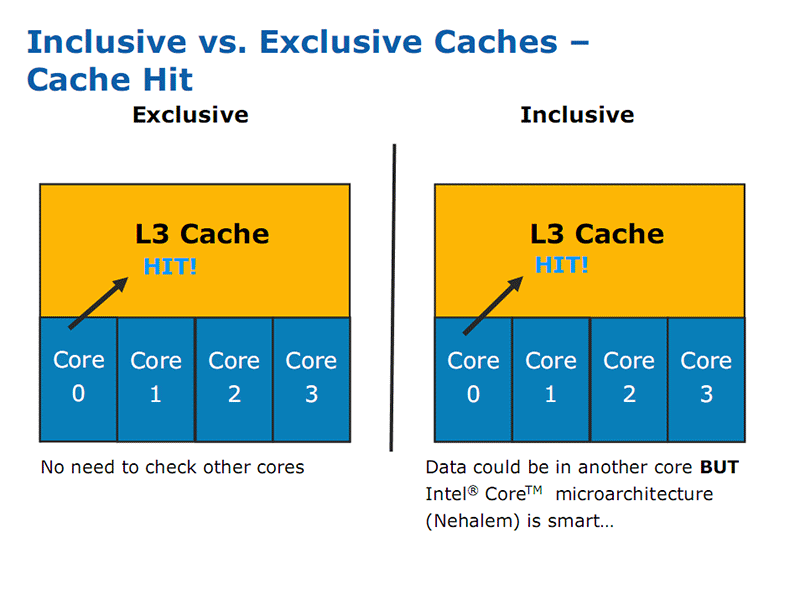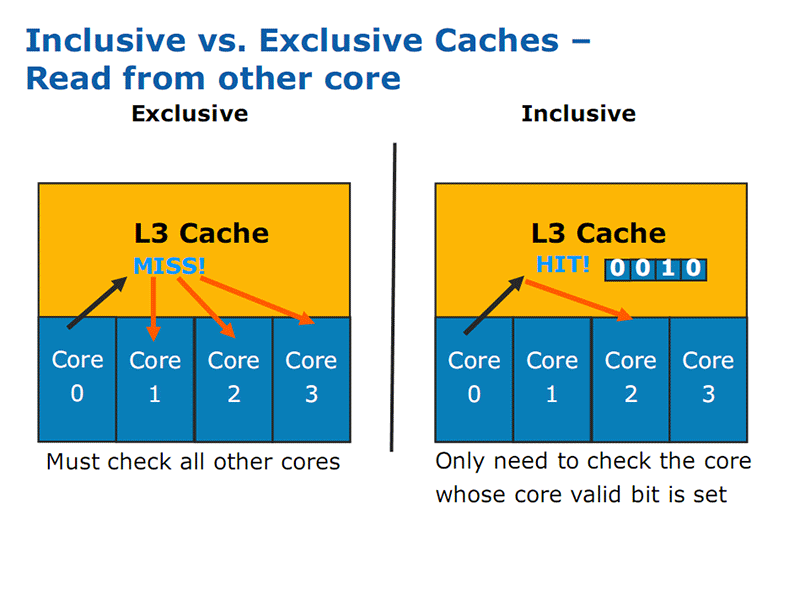



Click to enlarge
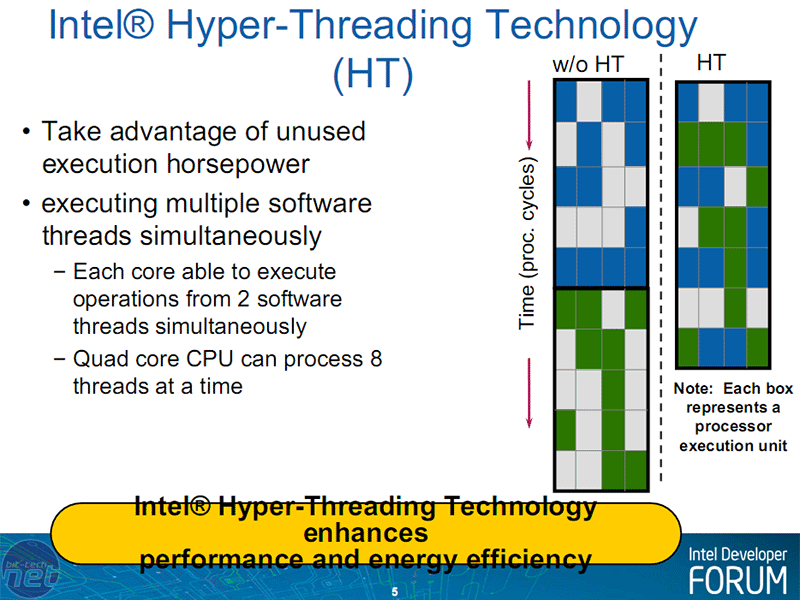
Hyper Thread a multi-multi-core
Simultaneous Multi-Threading (or SMT), branded as "Intel Hyper Threading Technology" (or HTT), makes a return as well. This technique allows use of multiple resources on a single core, for more than one executing thread. This can effectively a quad core be read as an octo-core within the OS, as it allows a maximum of two threads per core.HTT was first introduced back in the days of Netburst and the Northwood core, offering the use of greater IPC (instructions per clock cycle) given the long pipelines of Netburst. It was left out of Core microarchitecture as it was deemed "unnecessary" by Intel because of the very efficient pipeline. Sadly this lead to many associating a long pipeline with SMT to hide resource access latency, and when Intel announced it would reintroduce the technology with Core i7, some questioned if the pipeline had become long and inefficient once again.

Click to enlarge
However after testing HTT on Core i7 it seems Intel has chiselled out quite a lean machine that means Nehalem still uses an efficient pipeline built off the foundation of Core 2, but its "wider" design with more efficient memory access and inter-core discussion (L3 cache) should mean it delivers more efficient multi-thread handling whether it's Thread or Instruction Level Parallelism.
Whereas previously very few programs were multi-threaded during the Pentium 4 era - this saw generally little performance increase for using SMT, depending on how the program was written and how easily it was to shoehorn some Instruction Level Parallelism (ILP) out of it. In some cases, this ended up cache-thrashing as resources were competed for and it could also be partly why Core 2 dropped SMT. Core 2's efficient pipeline and improved memory predictors would have been butchered in some cases if the memory bandwidth was further competed for, and especially in a quad core if the data had to navigate between the two dies because it would put far more pressure on the inherently limited Front Side Bus model.
As Intel pushes multi-threading much harder to software developers as a means of performance improvements, it's clear that extremely threaded or resource uncompetitive software will benefit the most from SMT.
RELATED ARTICLES






MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.