
Quick Patch Interconnect
QPI, or Quick Path Interconnect was originally known as CSI or Common System Interface. This is Intel’s proprietary point to point protocol compared to the open standard HyperTransport technology that AMD has used since its K8 architecture. Indeed, it seems that integrating the memory controller into the CPU and adopting a fast, serial, direct connection architecture seems like an inevitable pairing as the earlier IBM POWER architecture again confirms this.Just like Intel's new CPU architecture, QPI faced a massive design challenge to transmit data in an efficient, low latency manor while most importantly it should be readily scalable depending on the application, but not require new software development that will hinder its uptake. Instead, it should be invisible to drivers. Unlike HyperTransport, which is deployed in many scenarios as a point to point data transfer technology, QPI is predominantly designed to be used between the CPU and other components like other CPUs, chipsets, I/O hubs and so on.
It's a huge step over Intel's previous Front Side Bus that was designed exclusively to go from CPU to a central northbridge (memory controller). While in single socket situations Intel could remain competitive with AMD, this technology scaled badly the more sockets were included, and it particularly fell flat when AMD launched its Opteron CPU. The problem is, AMD had everything to gain in the server market, while Intel’s mammoth market share also made it more difficult to vastly change its architecture without careful consideration on the impact to its business.
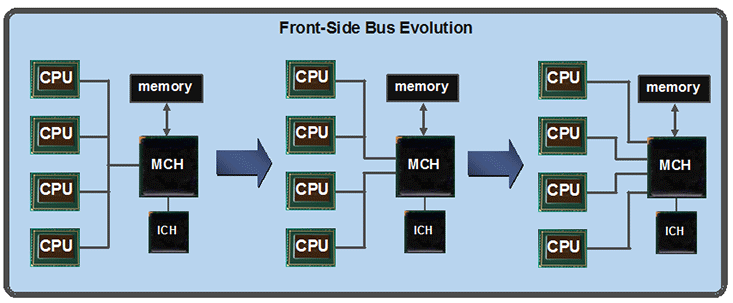
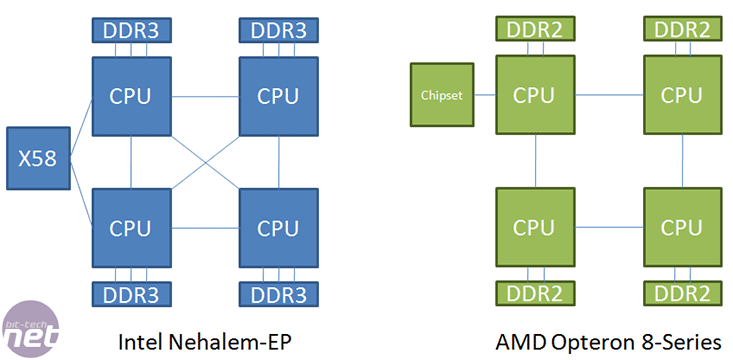
Intel follows AMD in the two to eight socket server area where each CPU has a local memory, yet can access remote memory as well. While the OS needs to be clever enough to determine what memory address is relevant to each socket in order to try and improve performance, it doesn't work if the software is highly threaded across multiple physical CPUs or if it runs out of local memory. In this case the NUMA factor is taken into account (remote access latency divided by local) and this is also down to how many CPU hops the data request has to jump. Intel claims that its design is still five percent more latency efficient than its current four socket Harpertown platform when accessing remote memory a hop away.
Compared to AMD, Intel only ever has to make one hop to check another CPU and its memory, however with AMD's K8 and K10, that can be as many as two in a four socket system. Couple in the fact that AMD is still using dual channel DDR2 compared to triple channel DDR3, and that HT 3.0 offers less bandwidth than a single QPI link, and we find that Intel's potential server performance is finally desirable again. The downside is the cost of upgrading as the whole server infrastructure has to be changed and QA’d; however when AMD upgrades its CPUs to DDR3 memory in the future, the same has to be done even if the CPUs still sit in socket F (LGA1207).
QPI works as direct point to point serial connection that uses low voltage differential signalling (LVDS) and cross-polarisation to allow very close wiring that avoids high frequency interference. Each single Link is divided into four quadrants, and of those four quadrants there are five differential pairs for bi-directional data traffic. This is why consumer applications with a single socket CPU and few I/O can drop down to a quarter of a QPI Link to save PCB space and cost, if the bandwidth isn’t needed.
The other benefit of splitting a single QPI link into four quadrants is redundancy – if one part of one quadrant fails the whole system can keep running by simply shutting down the bad quadrant. This is of huge importance to mission critical applications and a small performance drop is considerably more favourable to a whole system being offline, and the fact that the QPI link remains intact means the data hop count remains the same. The only problem we can see is if the single Link-wide clock generator function fails, the whole Link will cease to operate. That said, it’s no different from any other clock generator in the system.
The Core i7 CPUs that are announced today use a single QPI link and are designed for single socket system only, however Nehalem-EP will have two and future multi-socket Nehalem-EXs are believed to have even more still. The benefit Intel has designed into this architecture is again modularity in the Uncore segment, and the fact that QPI takes far fewer pins per link than its older Front Side Bus means it’s scalable within the same socket and keeps board designs relatively simple.
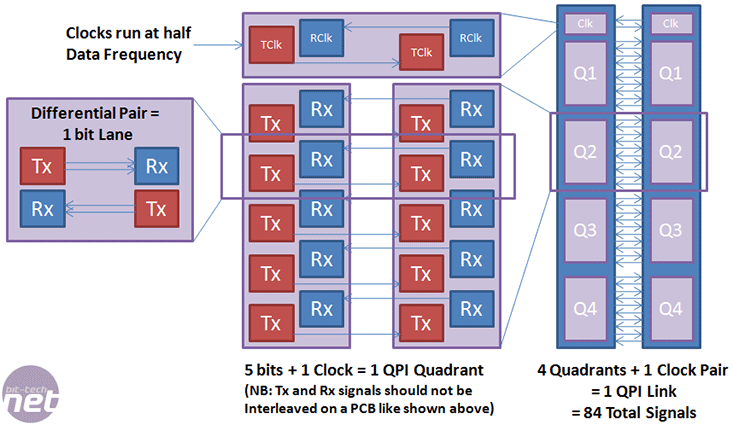
With respect to QPI bandwidth: each quadrant contains five differential pairs, called Lanes, which equate to five bits of data. With a bit of arithmetic this makes 20-bits for a full QPI link. 20-bits = 2.5 bytes and at 4.8-to-6.4GT/s equates to 12-to-16 GB/s, or bi-directionally this is a maximum of 24-to-32GB/s. However, each QPI flit packet is 80-bits in size, 64 of which (eight bytes) are used for data and the other 16-bits (two bytes) are used for protocol, flow control and CRC (error correction) data. This is just like all other point to point technology like HyperTransport and PCI-Express, where the actual usable data-rate will be one fifth lower than 24-to-32GB/s at 19.2-to-25.6GB/s.
In comparison, the latest HyperTransport 3.1 specification has more potential bandwidth at 51.2GB/s but its use is far more varied and this is with a "full" width equating to a 32-bit lane. However AMD K8 and K10 CPUs both use 16-bit HTT links offering 25.6GB/s bandwidth. HyperTransport can also auto-negotiate between 32 two-bit lane widths, but uses a 40-bit flit packet size regardless.
In a 64-bit address an extra 32-bits from a control packet are pre-appended for HyperTransport, whereas Intel's QPI doesn't need to as it has a larger native packet size. With that said, it's worth noting that HTT is more efficient with sub 32-bit data transfers since they are all padded to fit the size of the transferable packet.
QPI also has power saving techniques to scale frequency and/or link width like AMD's use of HyperTransport, making it suitable for battery limited mobile applications as well. It's likely, though, that not all mobile Nehalem CPUs will use an external QPI link and may have integrated graphics and PCI-Express integrated into the CPU instead.
RELATED ARTICLES






MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.