
Wide Dynamic Execution:
Simple Dynamic Execution of instructions and operations is a combination of a few factors: data flow analysis, speculative execution, out of order execution, and super scalar architecture. This has all been around since the "P6" Pentium Pro was introduced 12 years ago in November.Wide Dynamic Execution expanded on this with the introduction from the Core architecture which means a higher IPC (instructions per clock) rate as well as Micro and Macro Ops fusion. Intel has further enhanced this portion of the Core microarchitecture in this 45nm refresh - let's have a look at what's been added.
New Radix-16 Divider
The radix is an iterative divide and square root algorithm that's used commonly in computation, particularly gaming. Previous Intel micro-architecture used a radix-4 divider, where the number represents a "two to the bit-power". Therefore a radix-4 is two to the power of two, however the new radix-16 divider is simply two to the power of four. This means it can work on four bits of data per iteration which halves the loops needed to process the data, doubling the performance in this specific function. The other positive thing about this feature is that it's not dependent on any extra or specific code and will work on all existing software.

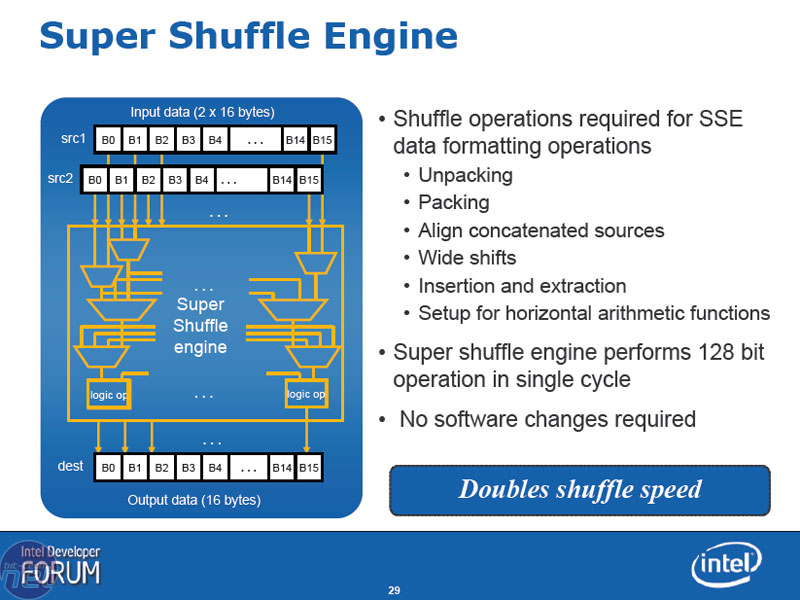
Super Shuffle Engine
Lots of SSE instructions deal with getting data into a vector form (two part - how much and a direction) as opposed to scaler (one part - either how much or a direction), which requires various shifting, packing or unpacking, inserting and extracting data into a parallel manner. The engine can perform these operations in a single clock cycle because the engine is now 128-bit wide (matching that of SSE instructions), which doubles the throughput from Conroe.Only the extract function takes more than one clock cycle because it's dependent on other factors outside of this engine, so naturally there are certain buffers and waits in other parts of the chip that affect performance.

Intel VTx Virtual Machine Architecture
The improvement with Virtual Machine management on Penryn is a reduction of context switch times by 25 to 75 percent as it provides more native micro-architectural control of both the guest and host states.Intels VMCS is a data structure for holding state data between guest(s) and host. For each one of these guests is a memory allocation that's invisible to everything else but the guest and VM Monitor, which keeps a track of where everything is. The VMCS approach is a more direct micro-architectural mechanism for managing the memory, and because it's integrated into the processor Intel does certain things to keep track of that memory. If the VMM doesn't modify something certain assumptions of transitions and references can be made without having to resort to complex algorithms to check these factors beforehand.
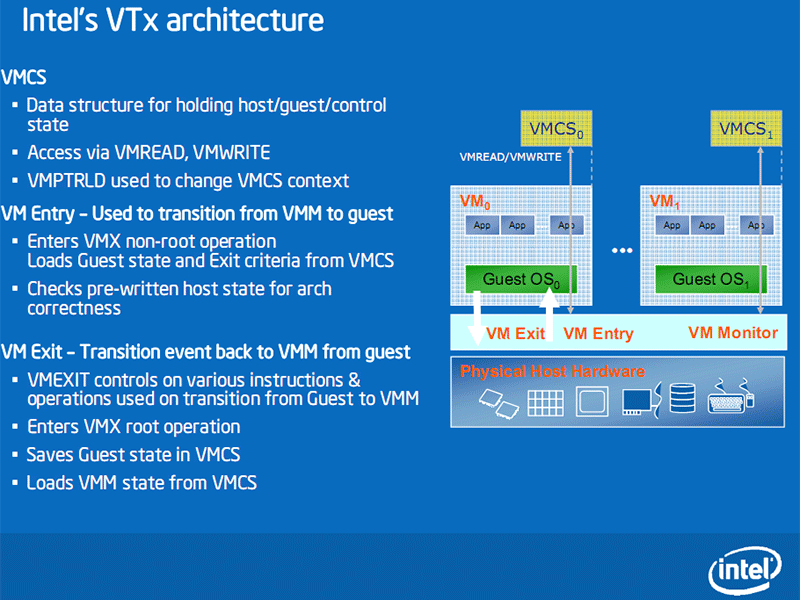
When transferring from the host to guest (VMM to VM) there has to be a consistency check for the loading state to be architecturally correct and consistent, and also the state when leaving the VM to VMM is again correct and consistent. This is what Intel calls its VMCS state management caching. By knowing what has changed and what hasn't, then the switch time can be reduced because no time intensive checks need to take place.
RELATED ARTICLES







MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.