
It wasn’t long ago when NVIDIA chose to introduce the first version of the GeForce 6200. This video card was based around the same NV43 GPU that could be found on the GeForce 6600 and 6600 GT, but had part of the chip disabled to give lower performance.
Today we are looking at the latest low-end card from NVIDIA, the GeForce 6200 TurboCache. This is a variant on the standard 6200 card that includes less on-board memory, but uses technology that allows the card to pool system RAM for rendering.

 The card itself is fairly small, and has no extra power connector. The card has a passive heatsink to keep the noise down, although this does get extraordinarily hot in use.
The card itself is fairly small, and has no extra power connector. The card has a passive heatsink to keep the noise down, although this does get extraordinarily hot in use.

 This 6200 TC card has 32MB of onboard memory with a 64-bit memory interface, but also grabs enough memory out of system to show up in Windows as a 128MB card. The 16MB version also shows up as a 128MB card in the driver, but with a 32-bit memory interface - the performance of this card will be slightly worse than what we have here.
This 6200 TC card has 32MB of onboard memory with a 64-bit memory interface, but also grabs enough memory out of system to show up in Windows as a 128MB card. The 16MB version also shows up as a 128MB card in the driver, but with a 32-bit memory interface - the performance of this card will be slightly worse than what we have here.
In order to explain how TurboCache works, we need to go back and take a look at a typical 3D graphics pipeline – one that makes use of local memory. There are four major stages in a typical GPU\'s pipeline – the first being the geometry processor which handles the geometry, transform and lighting data that is provided by the application. Once this process has been completed, the geometry is converted into pixels in the vertex processing engine.
Textures are then applied to the pixel in the fragment pipeline. Finally, these textures and pixels need to be rasterised in the final output stage of the rendering pipeline. Rasterisation is essentially the application of lighting and other such environmental effects which have an effect on the final pixel value. Once this is completed, the pixel values are stored in local memory that is located on the video card\'s PCB and then pumped out to the screen.
This is where things change with TurboCache technology, as there are architectural changes required to enable the GPU to render and texture to and from system memory with the greatest efficiency.
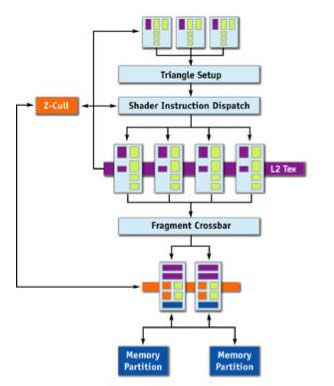
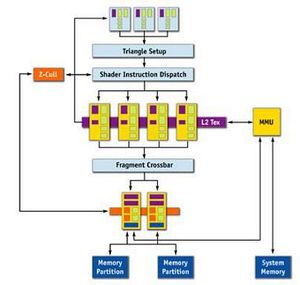
A normal 3D pipeline architecture vs The TurboCache architectureThere is a new Memory Management Unit (labelled MMU in the flow diagram), which allows the GPU to allocate and de-allocate system memory to the graphics processing, as well as read and write to that memory in an efficient manner. It is worth discussing the implications of using system memory to store pixels and surfaces, as it is clear that using the PCI Express interface to transfer data will be slower and have higher latency than transferring data on-board the graphics card.
In fact, with the relative performance of this GPU, the 4GB/s bi-directional bandwidth that the PCI-Express bus on a Pentium 4 can provide is not really an issue – the NV44 can render surfaces and textures adequately with the bandwidth that the interface can provide. There is still a latency issue, but simply put, it isn\'t the memory speed that is the bottleneck on this card!
However, typically, an Athlon 64 will deliver 5800-6000MB/s of memory bandwidth with fast DDR memory running at DDR400, so we can expect memory bandwidth intense game titles to perform better on a GeForce 6200 TurboCache/Athlon 64 combination than on a Pentium 4. The Athlon 64 is able to deliver better bandwidth because of the on-chip memory controller.
There are major performance hits that come from using compression dependant methods, including Anti-Aliasing. This is because the GPU does not make support any compression techniques, and the way that the pipeline was re-designed to minimise latency issues means that things like Anti-Aliasing run pretty slowly due to the way that textures are thrashed across the PCI-Express bus in most, if not all instances in a typical game scenario.
Today we are looking at the latest low-end card from NVIDIA, the GeForce 6200 TurboCache. This is a variant on the standard 6200 card that includes less on-board memory, but uses technology that allows the card to pool system RAM for rendering.
In order to explain how TurboCache works, we need to go back and take a look at a typical 3D graphics pipeline – one that makes use of local memory. There are four major stages in a typical GPU\'s pipeline – the first being the geometry processor which handles the geometry, transform and lighting data that is provided by the application. Once this process has been completed, the geometry is converted into pixels in the vertex processing engine.
Textures are then applied to the pixel in the fragment pipeline. Finally, these textures and pixels need to be rasterised in the final output stage of the rendering pipeline. Rasterisation is essentially the application of lighting and other such environmental effects which have an effect on the final pixel value. Once this is completed, the pixel values are stored in local memory that is located on the video card\'s PCB and then pumped out to the screen.
This is where things change with TurboCache technology, as there are architectural changes required to enable the GPU to render and texture to and from system memory with the greatest efficiency.
A normal 3D pipeline architecture vs The TurboCache architecture
In fact, with the relative performance of this GPU, the 4GB/s bi-directional bandwidth that the PCI-Express bus on a Pentium 4 can provide is not really an issue – the NV44 can render surfaces and textures adequately with the bandwidth that the interface can provide. There is still a latency issue, but simply put, it isn\'t the memory speed that is the bottleneck on this card!
However, typically, an Athlon 64 will deliver 5800-6000MB/s of memory bandwidth with fast DDR memory running at DDR400, so we can expect memory bandwidth intense game titles to perform better on a GeForce 6200 TurboCache/Athlon 64 combination than on a Pentium 4. The Athlon 64 is able to deliver better bandwidth because of the on-chip memory controller.
There are major performance hits that come from using compression dependant methods, including Anti-Aliasing. This is because the GPU does not make support any compression techniques, and the way that the pipeline was re-designed to minimise latency issues means that things like Anti-Aliasing run pretty slowly due to the way that textures are thrashed across the PCI-Express bus in most, if not all instances in a typical game scenario.




MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.