
We\'ve looked at what NVIDIA are doing to implement Multiple Graphics Cards into the enthusiast\'s sector again; now it is the turn of Alienware. Currently under development is their own implementation of this technology which will not only allow NVIDIA cards to be paired up, but also ATI and any other video card manufacturer who manufactures PCI-Express graphics cards. This technology has been developed to be used in conjunction with the newly released Tumwater chipset from Intel, which is designed for their Xeon processors.
Alienware have developed a driver-independent solution, which doesn\'t necessarily require support from the graphics card manufacturers. The system was designed to be independent of the video card drivers with the use of Alienware\'s Video Array which uses it\'s own software and a proprietary \"merger hub\". This hub is a 64-bit PCI-X expansion card that connects to both graphics boards together by synchronising the signals produced by each card, allowing for the scene to be rendered collectively by the two GPUs. This is then coupled with the Alienware X2 motherboard to give an alternative solution to what NVIDIA have come up with in their Scalable Link Interface. We don\'t have images of how the Alienware Video Array has been implemented at the moment, but no doubt when these become available to the press, we\'ll get our hands on them. The question is though, what are the differences between NVIDIA\'s SLI and Alienware\'s Video Array and which one looks to be the more preferable solution?
I feel that here is a good enough time to introduce the power requirements. At the E3 festival, Alienware had a demo system running dual PCI-Express graphics cards in conjunction with their merger hub. The power supply fitted in this system was rated at no less than 800 Watts – that\'s just simply insane!
So, how does these technologies work?
Both technologies have the same basic principle, which is to give a dramatic increase in graphics performance from your personal computer by using multiple graphics cards to render an image by working together. How is this done?
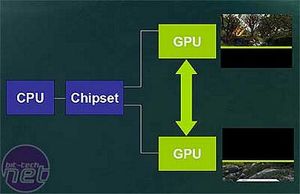 Firstly, the scene is split in half (well actually, it is closer to a 60/40 split) to allow each card to render half of the scene each; this is then combined together to give the final scene as one whole rendering. This allows each GPU to concentrate on a certain part of the scene, and thus, render it much more efficiently when there\'s a pair of GPUs working together.
Firstly, the scene is split in half (well actually, it is closer to a 60/40 split) to allow each card to render half of the scene each; this is then combined together to give the final scene as one whole rendering. This allows each GPU to concentrate on a certain part of the scene, and thus, render it much more efficiently when there\'s a pair of GPUs working together.
 Why do the cards not take a 50/50 split on the scene?
Why do the cards not take a 50/50 split on the scene?
 As you can see from this wireframe screenshot of Quake 3, there is a large concentration of polygons around the lower middle portion of the screen, with much less detail near the top of the screen. As the player moves through the room, the cards will dynamically adjust the crop line according to load.
As you can see from this wireframe screenshot of Quake 3, there is a large concentration of polygons around the lower middle portion of the screen, with much less detail near the top of the screen. As the player moves through the room, the cards will dynamically adjust the crop line according to load.
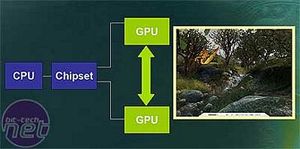
 From this screen grab from Far Cry, you will notice that the majority of the detail is actually in the bottom 80% of the scene, while the top 20% is taken up by the sky which doesn\'t take a great deal of GPU muscle to render it efficiently. The dynamic load balancing that is included in both of these technologies intelligently splits the image to ensure that the GPUs are given similar levels of load. The better this balance, the greater the speed increase; if one card is struggling to keep up, it will drag the overall FPS down as it synchs with the unloaded card.
From this screen grab from Far Cry, you will notice that the majority of the detail is actually in the bottom 80% of the scene, while the top 20% is taken up by the sky which doesn\'t take a great deal of GPU muscle to render it efficiently. The dynamic load balancing that is included in both of these technologies intelligently splits the image to ensure that the GPUs are given similar levels of load. The better this balance, the greater the speed increase; if one card is struggling to keep up, it will drag the overall FPS down as it synchs with the unloaded card.
With a game title running at 1600x1200, there are 1.92 million pixels to be drawn on screen in any one frame - giving that the threshold for the human eye is around 28 frames per second, a single card must draw close to 54 million pixels on screen per second in order for the game to be remotely playable. This is even before we\'ve added textures, pixel shaders and vertex shaders into the equation – also we cannot forget that today\'s cards render a few frames ahead of themselves to gain an much more accurate interpretation of the scene. They do this by rendering the scene several times over and then offsetting each of the pixels and returning the average of the multiple renderings of the scene to construct the final image.
Take a game such as Far Cry for example; in my last X800 review, you will see that it rendered Far Cry at 1280x1024 (1.31m pixels per frame) with 4xAA 8xAF at around 40 FPS. With two X800PRO\'s using Alienware\'s Video Array, you could expect to render that at close to 70 FPS providing the array is not limited by the system processor. In simple terms, the two cards are assigned to render half of the scene each, thus halving the workload of each card. The reasoning for it not being a 100% increase is the system overheads – considering that a 3800+ limits an X800PRO; the limitation is even more apparant from my initial testing of a 6800 Ultra in some game titles, there\'s going to be a huge limit in CPU power. Hopefully with new games just around the corner, such as Doom III and Half Life 2, we can expect to see there to be less of a CPU bottle neck due to the heavy requirements that are being placed on the GPU(s) by the game title.
Alienware have developed a driver-independent solution, which doesn\'t necessarily require support from the graphics card manufacturers. The system was designed to be independent of the video card drivers with the use of Alienware\'s Video Array which uses it\'s own software and a proprietary \"merger hub\". This hub is a 64-bit PCI-X expansion card that connects to both graphics boards together by synchronising the signals produced by each card, allowing for the scene to be rendered collectively by the two GPUs. This is then coupled with the Alienware X2 motherboard to give an alternative solution to what NVIDIA have come up with in their Scalable Link Interface. We don\'t have images of how the Alienware Video Array has been implemented at the moment, but no doubt when these become available to the press, we\'ll get our hands on them. The question is though, what are the differences between NVIDIA\'s SLI and Alienware\'s Video Array and which one looks to be the more preferable solution?
I feel that here is a good enough time to introduce the power requirements. At the E3 festival, Alienware had a demo system running dual PCI-Express graphics cards in conjunction with their merger hub. The power supply fitted in this system was rated at no less than 800 Watts – that\'s just simply insane!
So, how does these technologies work?
Both technologies have the same basic principle, which is to give a dramatic increase in graphics performance from your personal computer by using multiple graphics cards to render an image by working together. How is this done?
With a game title running at 1600x1200, there are 1.92 million pixels to be drawn on screen in any one frame - giving that the threshold for the human eye is around 28 frames per second, a single card must draw close to 54 million pixels on screen per second in order for the game to be remotely playable. This is even before we\'ve added textures, pixel shaders and vertex shaders into the equation – also we cannot forget that today\'s cards render a few frames ahead of themselves to gain an much more accurate interpretation of the scene. They do this by rendering the scene several times over and then offsetting each of the pixels and returning the average of the multiple renderings of the scene to construct the final image.
Take a game such as Far Cry for example; in my last X800 review, you will see that it rendered Far Cry at 1280x1024 (1.31m pixels per frame) with 4xAA 8xAF at around 40 FPS. With two X800PRO\'s using Alienware\'s Video Array, you could expect to render that at close to 70 FPS providing the array is not limited by the system processor. In simple terms, the two cards are assigned to render half of the scene each, thus halving the workload of each card. The reasoning for it not being a 100% increase is the system overheads – considering that a 3800+ limits an X800PRO; the limitation is even more apparant from my initial testing of a 6800 Ultra in some game titles, there\'s going to be a huge limit in CPU power. Hopefully with new games just around the corner, such as Doom III and Half Life 2, we can expect to see there to be less of a CPU bottle neck due to the heavy requirements that are being placed on the GPU(s) by the game title.





MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.