Researchers boost neural network dev 200x
March 25, 2019 | 10:05
Companies: #massachusetts-institute-of-technology
Researchers at the Massachusetts Institute of Technology (MIT) claim to have developed a new algorithm for the development of neural networks which runs up to 200 times more efficiently than current state-of-the-art implementations - potentially opening up artificial intelligence development to a wider audience.
Neural networks are the hot topic of the day: From Nvidia's divisive deep learning super sampling (DLSS) to the Go mastery of DeepMind's AlphaGo Zero, neural networks are revolutionising a range of industries. There's only one small snag: While it's possible to have a neural network be designed automatically by a computer, it takes considerable resources.
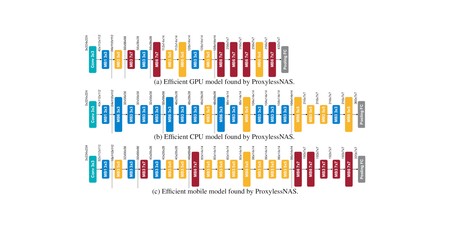
A recently-released neural architecture search (NAS) algorithm developed by Google, which is designed to produce a convolutional neural network (CNN) for image classification, chewed through a claimed 48,000 hours of GPU processing time before coming up with its solution - something MIT researchers point out is only available to an organisation with either considerable resources or even greater patience. The solution: a new NAS algorithm which, they claim, can produce a similar CNN in just 200 GPU hours - just over a week when running on a single GPU.
'We want to enable both AI experts and non-experts to efficiently design neural network architectures with a push-button solution that runs fast on a specific hardware,' explains co-author Song Han of his team's work towards what he describes as democratising artificial intelligence. 'The aim is to offload the repetitive and tedious work that comes with designing and refining neural network architectures.'
The team's algorithm not only produces the networks in a far shorter time than the competition, but the networks it comes up with are claimed to be more efficient: Running on a smartphone, the image classification CNNs provide to be around 1.8 times faster than the current gold standard in the industry. Interestingly, some of these networks used architectures that had previously been dismissed as being too inefficient - but because they had been optimised for their target hardware, ran considerably faster than the competition.
The team's paper, ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware, is available via arXiv.org (PDF warning) and is to be presented at the International Conference on Learning Representations this May.






MSI MPG Velox 100R Chassis Review
October 14 2021 | 15:04

Want to comment? Please log in.